
List Interface와 구현체간의 비교
일단 List를 알기전 Array를 알아보자.
Array(배열)
정의
- 동일한 타입의 여러 원소를 선형 집합으로 관리하는 정적 데이터 구조
- 선형: 데이터가 순차적으로 저장되는 구조, 순서가 있는 데이터의 집합
- 정적: 생성과 동시에 크기가 고정되어 늘릴 수 없다.
- 메모리상에 일렬로 저장되어 Random Access가 가능하다.
- Random Access: 데이터의 위치(인덱스)를 알고 있다면 한 번에 접근이 가능한 특성
메소드

특징
- 원소에 접근하고 변경하는 것은 빠르다.
- 중간 원소를 추가/삭제시 연속적인 상태를 유지하기 위해 원소를 옮기는 작업이 필요하다.
List
- 동일한 타입의 여러 원소를 선형 집합으로 관리하는 동적 데이터 구조
- 동적: 원소가 추가/삭제됨에 따라 크기가 변경 될 수 있음.
- List Interface 구현체에 따라 특성이 다름.

- ArrayList
- index를 통한 원소 접근이 빠름, 원소의 삽입/제거가 느림
- LinkedList
- index를 통한 원소 접근이 느림, 원소의 삽입/제거가 빠름
- Vector
- ArrayList와 비슷하며 thread-safe하기에 비교적 느릴 수 있음.
메소드

특징
- 순서가 있는 Collection 인덱스를 통한 원소 접근 가능
- 동일한 원소 저장 가능, ListIterator를 제공
- Collection: Java에서 객체의 그룹을 저장하고 처리할 수 있는 프레임워크로, List, Set, Queue 등의 인터페이스를 포함
- ListIterator: List 인터페이스의 양방향 순회를 지원하는 반복자로, 순방향/역방향 이동, 수정, 추가, 삭제 등의 작업이 가능
ArrayList
- 동적 배열을 사용한 List 구현체
- 원소가 추가될 때 남은 공간이 없다면 크기를 일정 배수로 늘린 배열을 만들어 기존 원소를 옮긴
- 원소가 배열에 저장되어 있기 때문에 지정한 위치의 원소 접근이 빠르다.
- 중간 원소의 삽입/제거 연산은 기존 배열 연산과 같이 해당 위치 이후의 모든 원소를 이동시키므로 느리다.
- size: 실제 원소 개수
- elementData: 원소 보관함
- capacity: 원소 보관함 크기
코드 구현
// 새로운 ArrayList를 생성하면 capacity 크기의 배열이 함께 생성된다.
class MyArrayList<E> {
private static final int DEFAULT_CAPACITY = 10;
private int size = 0;
private Object[] elementData;
public MyArrayList() {
elementData = new Object[DEFAULT_CAPACITY];
}
public MyArrayList(int initialCapacity) {
elementData = new Object[initialCapacity];
}
}
- 원소 추가하기, 공간이 부족하다면 capacity 늘리기
// 원소 추가(add)
public void add(E e) {
// size가 모두 찼으면 capacity를 눌려주자.
if (size == elementData.length)
growCapacity();
elementData[size++] = e;
}
// 새로운 배열을 선언 후 기존 배열 옮기기 시간복잡도: O(N)
private void growCapacity() {
int newCapacity = elementData.length + (elementData.lenght >> 1);
elementData = Arrays.copyOf(elementData, newCapacity);
}
- 원소 접근, 삽입, 제거(get, insert, remove)
// get,이미 배열에 저장되어 있으니 접근시 O(1)
public E get(int idx) {
return (E)elementData[idx];
}
// idx 위치에 삽입하기, 삽입 후 한칸씩 옮기기 O(N)
pulbic void insert(int idx, E e) {
if (size == elementData.length) growCapacity();
System.arraycopy(elementData, idx, elementData, idx + 1, size++ - idx);
elementData[idx] = e;
}
// remove, idx 위치 요소 제거하기, 삭제 후 한칸씩 앞당기기 O(N)
public void remove(int idx) {
int copyLenth = elementData.lenght - idx + 1;
System.arraycopy(elementData, idx + 1, elementData, idx, copyLength);
size--;
}
LinkedList
- 차례로 연결된 Node를 사용한 구현체
- Node: 데이터와 다음/이전 Node를 가리키는 참조값을 가진 LinkedList의 기본 구성 요소이다.
- 원소가 추가/삭제될 때마다 해당 원소의 Node가 추가/삭제된다.
- 지정된 위치의 원소에 접근하기 위해서는 선형 탐색이 필요하다.
- 순차적인 접근 시 Iterator를 사용해 효율적으로 관리할 수 있다.
- Iterator: 컬렉션의 요소들을 순차적으로 접근하고 순회할 수 있게 해주는 인터페이스이다.
- 중간 원소 삽입/제거 연산은 해당 Node와 연결된 참조값만을 갱신하여 다른 Node에 영향을 미치지 않는다.

- 원소마다 Node에 값을 가지고 다른 Node를 가리키는 link를 통해 연결을 유지한다.
- addLast: lastNode의 next에 Node 연결
- addFirst: 새 Node의 next에 firstNode 연결
코드 구현
// LinkedList를 간단하게 구현하기
class MyLinkedList<E> {
private int size = 0;
private Node<E> firstNode = null;
private Node<E> lastNode = null;
public static class Node<E> {
E item; // 원소
Node<E> next; // 연결성을 가지기 위해 다음 Node
Node(E element, Node<E> next) {
this.item = element;
this.next = next;
}
}
MyLinkedList.Node<Integer> node = list.getFirstNode();
while(node != null) { // lastNode는 null을 갖고 있다.
System.out.println(node.item);
node = node.next; // 각 node는 next를 통해 다음 Node를 가르킨다.
}
- 원소 추가 방법(add)

// addLast(int idx)
// 기존 lastNode에 newNode를 연결 후 lastNode가 항상 가장 끝 노드를 가르키도록 갱신 O(1)
public void addLast(E element) {
Node<E> newNode = new Node<>(element, null);
if(size == 0) firstNode = newNode; // size가 0이면 비어있는 상태, Node는 하나
else lastNode.next = newNode;
lastNode = newNode;
size++;
}
// addFirst(int idx)
public void addFirst(E element) {
Node<E> newNode = new Node<>(element, firstNode);
if(size == 0) lastNode = newNode;
fistNode = newNode;
size++;
}
- 원소 접근 방법(get)
public Node<E> getNode(int idx) {
Node<E> currentNode = firstNode;
// 특정 위치의 노드에 접근하기 위해서는 선형 탐색이 필요 O(N)
while(idx --> 0)
currentNode = currentNode.next;
return currentNode;
}
public E get(int idx) {
return getNode(idx).item;
}
- 원소 삽입 방법(insert)

// Node에 삽입을 하는 경우, 시간복잡도 O(1)
// 기존 prevNode.next를 먼저 바꾸면 newNode의 next가 사라지므로 newNode.next로 먼저 연결한다.
public void insert(Node<E> prevNode, E element) {
Node<E> newNode = new Node<>(element, prevNode.next);
prevNode.next = newNode;
if (newNode.next == null) // newNode의 next가 null이면 lastNode에 추가 되는 것.
lastNode = newNode;
size++;
}
// idx번째에 추가하는 방법.
public void insert(int idx, E element) {
if (idx == 0) addFirst(element);
else if (idx == size) addLast((element));
else insert(getNode(idx - 1), element));
}
- 원소 삭제 방법(remove)
// 만약 prevNode가 아닌 targetNode만 전달받았다면 prevNode.next를 변경하기 위해 targetNode를 next로 가리키고 있는 prevNode를 선형탐색을 통해 찾아야한다.
public void removeNext(Node<E> prevNode) {
if (prevNode.next == null) return ;
//prevNode.next를 next.next로 바꾸면 기존 prevNode.next를 삭제할 수 있다.(garbage 콜렉터에 의해 삭제)
prevNode.next = prevNode.next.next;
if (prevNode.next == null) // 이전 노드의 next가 null이면 라스트이다.
lastNode = prevNode;
size--;
}
// idx를 받아 삭제하는 경우
public void remove(int idx) {
if (idx == 0) removeFirst();
else removeNext(getNode(idx - 1));
}
위의 방법들을 구현한 것들이 java.util.List
라이브러리를 사용하면 편하게 add, get, remove를 사용할 수 있다.
ArrayList와 LinkedList의 장단점을 알아야지 효율적이게 알고리즘을 구현할 수 있다.
예를들어, get이 필요한 경우 Arraylist를 사용하면 시간복잡도가 O(1)이므로 효율적이다.
LinkedList 같은경우 전체 시간복잡도가 O(N^2)이 될 수 있다.
순차적 접근은 ListIterator를 사용하는 것이 좋다.
배열과 리스트 구현체의 선형 자료구조의 대표 기능 수행에 대한 시간복잡도 비교
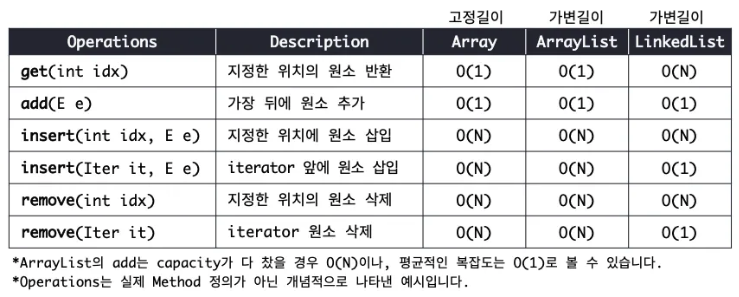
결론
Array와 List는 모두 선형 데이터 구조를 다루는 중요한 도구이다. Array는 고정 길이의 정적 데이터 구조로, Random Access가 가능하여 원소 접근과 변경이 O(1)로 매우 빠르다는 장점이 있다. 하지만 중간 원소의 삽입/삭제 시 다른 원소들을 이동시켜야 하는 O(N) 비용이 발생한다.
반면 List는 동적 데이터 구조로, ArrayList와 LinkedList 두 가지 주요 구현체가 있다. ArrayList는 Array를 기반으로 하여 크기가 동적으로 조절되며, Array와 유사한 성능 특성을 보인다. LinkedList는 Node들을 연결하여 구현되어 있어, 중간 원소의 삽입/삭제가 O(1)로 빠르지만, 특정 위치의 원소에 접근하기 위해서는 O(N)의 선형 탐색이 필요하다.
따라서 데이터의 크기가 고정적이고 잦은 접근이 필요한 경우에는 Array나 ArrayList를, 데이터의 크기가 가변적이고 빈번한 삽입/삭제가 필요한 경우에는 LinkedList를 사용하는 것이 효율적이다. 또한 순차적 접근이 필요한 경우에는 Iterator를 활용하여 효율적으로 데이터를 순회할 수 있다.
'알고리즘 > List' 카테고리의 다른 글
| [백준/Silver IV] 요세푸스 문제 - 1158 (0) | 2024.05.22 |
|---|---|
| [백준/Silver II] 에디터 - 1406 (0) | 2024.05.15 |