
RAM & ROM
메인 메모리에는 두개의 하드웨어가 존재한다. 바로 RAM과 ROM
간단하게 설명하면 RAM은 Random Access Memory로 어떤 주소에 접근하든 소요되는 시간이 동일하다, 임의의 위치에 접근 하는 시간이 동일하다는 뜻이다.
그렇다면 ROM은 Read Only Memory로 읽기 전용이라는 뜻이다.
MainMemory는 램과 롬이 있지만 보통 램을 지칭하는 경우가 많다
RAM
- 휘발성 저장장치, 전원이 꺼지면 데이터가 모두 사라진다.
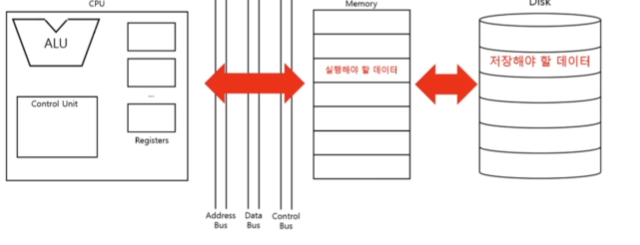
- 메모리에서 실행해야 할 데이터를 저장하고 있다.
- 크기가 클수록 빠르게 실행하기 유리하다. 그 이유는 메모리 크기가 크다면 보조기억장치에서 많은 데이터를 갖고와서 저장할 수 있다. CPU는 보조기억장치에 있는 데이터를 가져오려면 Memory를 통해 가져와야 한다.
DRAM(Dynamic RAM)
- 시간이 지나면 동적으로 저장된 내용이 사라진다. 그래서 주기적으로 DRAM을 재충전(refresh)한다
- 메인메모리에서 주로 사용되는 RAM인데 그이유는 대용량화에 좋은 성능을 보인다.
SRAM(Static RAM)
- 시간이 지나도 사라지지 않는다,
- Cache Memory에 사용된다.
SDRAM(Synchromous Dynamic RAM)
- 클럭 신호와 동기화된 DRAM이다, DRAM의 발전형 형태
- 클럭 신호에 맞춰 CPU와 정보를 주고 받을 수 있는 RAM이고 CPU에서 접근하기가 용이하여 성능이 뛰어나다.
DDR SDRAM(Double Data Rate SDRAM)
- 대역폭을 넓혀서 속도를 늘릴 수 있는 SDRAM이다. 대역폭이란, Memory에 접근하기 위한 통로의 넓이이다.
- SDR를 Single Data Rate RAM이라고 하는데 DDR은 대역폭이 두배이다.
- 그렇다면 DDR2는 2^2, DDR3는 2^3, DDR4는 2^4
 플래시 메모리
플래시 메모리- Read Only Memory
- 부팅이 될 때 가장 먼저 실행 되는 저장 장치이다.
- Mask ROM: 가장 기본적인 형태의 ROM,옛날 가전제품에서 사용
- PROM: Programmable ROM: 데이터를 한 번 새길 수 있는 꺠ㅡ
- EPROM: 한 번 지우고 다시 저장가능한 ROM(전기신호 혹은 자외선)
리틀 엔디안과 빅 엔디안- EPROM의 발전된, 저렴한 형태, 반도체 기반의 저장장치,
- 범용성이 넓어 오늘 전자제품에서 많이 사용됨.
- 보조기억장치에서도 사용된다.(USB, SSD)
- 둘 중 무엇이 더 좋은 것은 없다. 엔디안의 유래가 달걀의 작은 부분을 먼저 깨냐, 큰 부분을 먼저 깨냐 라는 유래에서 왔다. 즉 둘 중 좋은 것은 없다는 의미.

메모리에 데이터를 넣는 순서에 맞춰 리틀 엔디안과 빅 엔디안으로 나눠진다.
- 일반적으로 메모리는 byte 단위로 저장
- CPU로 부터 메모리가 받아들이는 데이터는 4byte(32bit), 8 byte(64bit), 워드(word)단위
- 1byte 씩 저장하는 메모리의 경우 4byte 데이터는 4개의 주소에 걸쳐 저장 되고 8byte는 8개의 주소에 걸쳐 저장이된다.
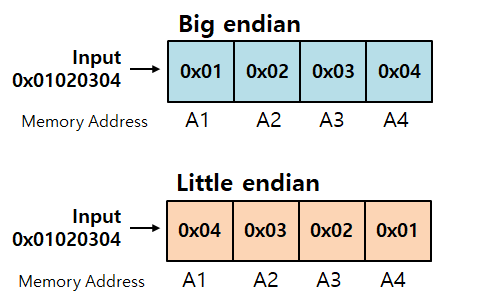
- 만약 16진수인 1A2B3C4D가 있으면 1A, 2B, 3C, 4D로 나누어 4개의 주소에 저장된다.
엔디안
- 연속해서 저장해야 하는 바이트를 저장하는 순서
- 순서가 달라지면 리틀, 빅으로 분류하는데 다른 분류 방법도 있다.
빅 엔디안
- 낮은 번지 주소부터 상위바이트부터 저장하는 방식
- 상위 바이트는 수를 이루는 가장 큰값(MSB) 혹은 가장 처음으로 접근하는 글자
- 1A2B3C4D가 저장되는 순서는 1A, 2B, 3C, 4D로 저장된다.
- 직관적이기 때문에 메모리 값을 직접 읽기 편리하고 디버깅에 좋다.

리틀 엔디안
- 빅 엔디안과 반대
- 낮은 번지 주소부터 하위바이트부터 저장하는 방식
- 하위 바이트는 수를 이루는 가장 작은 값(LSB) 혹은 가장 나중에 접근하는 글자.
- 1A2B3C4D가 저장되는 순서는 4D, 3C, 2B, 1A로 저장된다.
- 현재 CPU가 많이 사용되는 방법인데 계산하기 용이하여 사용된다.
- 자리올림이나 수치계산에서 뒤로 저장하는 방법이 유리하다.

사실 고려해야 했다.
서로 다른 시스템 간에 데이터를 전송할때에는 엔디안을 고려해야 하는데 오늘날의 데이터 송수신간에 사용자가 엔디안을 고려하지 않는 이유는 네트워크 전송시 엔디안이 빅엔디안으로 통일되었기 때문이다.
예전에는 NUXI Problem이 있었다.
NUXI Problem은 UNIX를 전송했는데 NUXI로 보인 문제이다.
논리주소와 물리주소
실행 중인 프로그램이 적재되는 메모리주소는 시시때때 바뀔 수 있다.
같은 프로그램을 두 번 실행하면 다른 메모리에 적재될 수 있다.
CPU는 메모리에 있는 명령어를 통해 작업을 실행하는데 CPU가 현재 메모리에 어떤 주소에 명령이 있는지 모두 알 수 있을까? 불가능하다
- 그렇다면 어떻게 CPU는 시시 때때로 적재된 프로그램의 주소를 찾아가는 걸까?
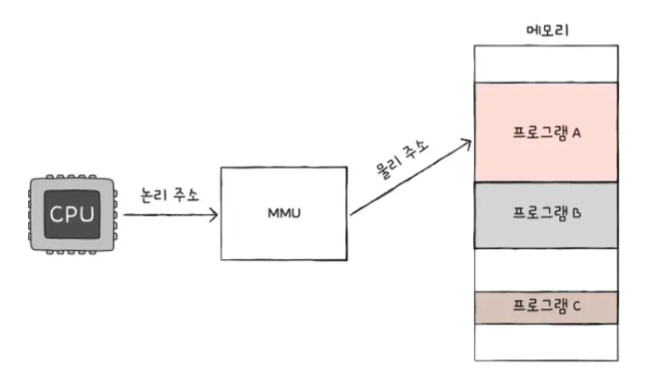
- 사실 주소 체계에는 두 종류가 있다. 논리 주소와 물리 주소이다.
- 물리 주소: 실제 메모리의 하드웨어 상의 주소, 고유한 주소를 의미한다.
- 논리 주소: CPU와 실행 중인 프로그램이 사용하는 주소(0번지부터 시작)
- 모든 프로그램은 0번지부터 시작하는 각자의 논리 주소를 사용한다.
- CPU는 0번지부터 시작하는 각 프로그램의 논리 주소를 인출/해석/실행한다.

주소 변환
CPU/프로그램이 사용하는 주소 체계(논리 주소)와 메모리가 사용하는 주소 체계(물리 주소)가 다르다면 어떻게 문제없이 부품 간 통신이 가능할까?
- MMU(Memory Management Unit)을 이용하여 논리 주소와 물리 주소간의 변환을 하면 된다!
MMU의 기본 동작
- 베이스 레지스터를 활용한 주소 변환
- 베이스 레지스터 = 기준 주소
- 논리 주소 = 기준주소로부터 떨어진 거리
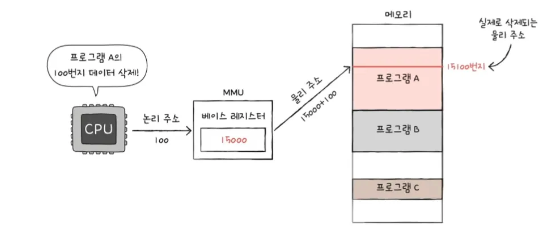
- 한계 레지스터도 있다. 만약 논리주소 10000번지에 있는 데이터에 접근하라 명령을 내리면 실행이 될까? 물리 주소의 범위를 벗어나지 않게 한계 레지스터를 사용한다. 한계 레지스터에는 프로그램 크기가 적재되어 있다.
저장 장치 계층 구조와 캐시 메모리
저장 장치 계층 구조는 메모리 계층구조라고도 많이 사용한다.
Memory는 RAM, ROM이란 말도 있어서 혼란을 방지하고자 저장 장치 계층 구조라고 이야기 할 것이다.
CPU와 멀어질수록 저장 장치의 특성
- 레지스터 vs 메인 메모리
- 레지스터는 메인메모리에 비해 CPU가 레지스터의 접근이 빠르다. 가격도 비싸다, 저장공간은 훨씬 작다
- 메인 메모리 vs 보조기억장치
- 메인 메모리는 보조 기억장치에 비해 접근이 빠르고 가격도 비싸다, 저장공간은 작다.
- 보조기억장치 vs 클라우드 저장장치
- 보조기억장치는 클라우드 저장장치에 비해 접근이 빠르고 가격도 비싸다, 저장공간은 작다.
- 즉, 빠른 접근 속도와 큰 용량이 양립하기 어렵다.
아래 이미지와 같이 CPU와 가까운 순으로 저장 장치를 계층적으로 나타낸 것, 저장 장치 계층 구조라고 한다.
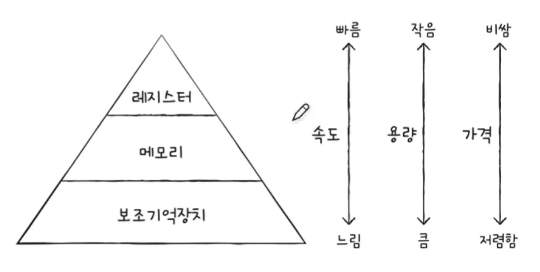
메모리와 레지스터간의 속도 차이
- CPU가 아무리 빨리 정보를 처리해도 메모리가 발맞춰주지 않으면 의미가 없다.
- 그래서 등장한 것이 캐시 메모리
캐시 메모리
- CPU와 메모리간의 속도 차이를 극복하기 위해 탄생
- CPU와 메모리 사이에 위치, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반
- CPU에서 사용할 법한 정보를 미리 가져와 저장
- 메모리가 대형 마트라면 캐시 메모리는 편의점, 사용자가 주로 많이 사용할만한 데이터가 있다.
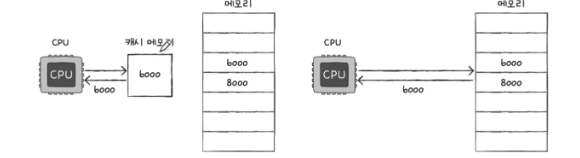
- 아래 이미지처럼 캐시메모리를 이용하여 메모리에 접근하지 않아 속도가 향상하는 경우를 캐시 히트라고 한다. 그 반대는 캐시 미스
- 캐시 히트율: 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
여러 단계의 캐시 메모리
- L1 캐시 메모리, CPU와 가깝고 용량 작음
- L2 캐시 메모리
- L3 캐시 메모리, CPU와 멀고 용량 큼
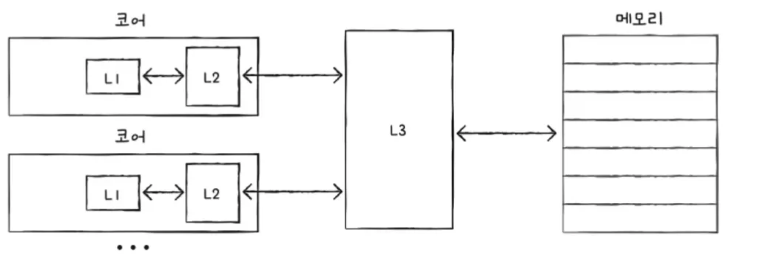
- 더 나아가서 분리형 캐시도 있다.
- L1D(데이터 저장) + L1l(명령어 저장)
캐시 메모리는 어떤 데이터를 저장하나
- CPU가 자주 사용할 법한 내용(예측)
- 참조 지역성의 원리를 이용하여 데이터를 갖고 온다.
- 시간 지역성: CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있음
- 공간 지역성: CPU는 접근한 메모리 공간 근처를 다시 접근하려는 경향이 있음.
- 아래 이미지를 보면 공간 지역성의 원리를 볼 수 있다.(기능 단위로 뭉쳐있음)
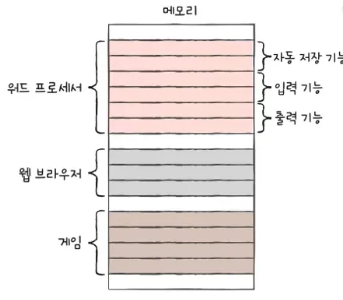
캐시 친화적 코드
- 캐시 미스가 최소화되는 코드이다. 즉, 시간 지역성 / 공간 지역성을 준수 하는 코드
- 아래 코드는 이차원 배열을 생성하는 코드이다.
# matrtx라는 변수 생성
# 10000x10000 크기의 2차원 리스트(또는 배열) 저장
# 이 리스트의 모든 요소를 0으로 초기화
matrix = [[0] * 10000 for _ in range (10000)]
for i in range(10000):
for j in range(10000):
matrix[i][j] = 1
위의 코드는 아래처럼 이차원 배열에 저장이 될 것이다.
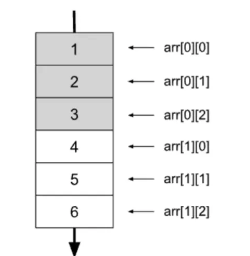
캐시 친화적이지 않은 코드
아래 코드를 실행하면 순차적으로 저장하는 것이 아닌 왔다 갔다 저장하게 된다.
즉 캐시 미스가 많이 나는 코드이다.
# matrtx라는 변수 생성
# 10000x10000 크기의 2차원 리스트(또는 배열) 저장
# 이 리스트의 모든 요소를 0으로 초기화
matrix = [[0] * 10000 for _ in range (10000)]
for i in range(10000):
for j in range(10000):
matrix[j][i] = 1 // 이 부분이 달라졌다. i j -> j i로 변경
실제로 실행을 하게 된다면 아래 처럼 시간이 2배정도 되는 것을 확인할 수 있다.

'Computer Science > Computer Architecture' 카테고리의 다른 글
| [Computer Science] [컴퓨터구조] 보조기억장치와 입출력장치 (1) | 2024.12.20 |
|---|---|
| [Computer Science] [컴퓨터구조] CPU(2) (0) | 2024.12.16 |
| [Computer Science] [컴퓨터구조] CPU (0) | 2024.12.14 |
| [Computer Science] [컴퓨터 구조] 데이터 (1) | 2024.12.13 |
| [Computer Science] [컴퓨터구조] 명령어 (4) | 2024.12.12 |