
728x90
[컴퓨터 구조] 멀티코어와 멀티 프로세서
멀티코어와 멀티 프로세서 부분은 빠른 CPU를 위한 하드웨어적인 설계로 볼 수 있다.
빠른 CPU를 만들고 싶다면 CPU의 성능을 끌어올리고 싶다면 어떻게 CPU를 설계해야 할 까?
CPU의 성능을 끌어올리는 아주 기본적인 내용
- 컴퓨터 부품은 클럭 신호에 맞춰 일사분란하게 움직인다.
- CPU는 클럭 신호(제어장치가 클럭신호를 받아냄)에 따라 명령어 사이클에 맞춰 명령어를 실행한다.
클럭 신호를 바르게 반복한다면?
- 박자가 빨라지고 명령어 사이클이 빨라진다.
- 실행속도가 더 빨라지는 것이 일반적.
- 클럭 속도가 높은 CPU는 일반적으로 성능이 좋다.
- 클럭 속도(Hz): 1초에 반복된 클럭의 횟수로 측정 1Hz, 1GHz = 10^9Hz(오늘날 CPU 속도)
- 좋은 CPU 일수록 클럭속도가 높은 것을 볼 수 있다.

CPU 오버클럭킹
- 임의로 클럭속도를 끌어 올리는 기술
- 오버(Over) + 클럭(Clock)
- 부팅시 BIOS에서 설정 가능
- BIOS: 하드웨어와 맞닿아 있는 기본적인 설정을 다룰 수 있다.
클럭과 발열의 관계
- 모든 부품에서 발열이 민감한 부푼이 CPU이다.
- 그러면 클럭 수를 엄청 높인다면 성능이 비례하여 상승할까?
- 아니다. 클럭 수가 높아질수록 발열 문제가 심각해지기 때문이다.
코어와 멀티코어
- 클럭 수 이외에 성능을 높이는 방벙은 코어 수를 늘리는 것.
- 즉, 멀티 코어 프로세서이다.
- 코어는 명령어를 인출하고, 해석하고, 실행하는 CPU 내 부품

스레드와 멀티스레드
- 스레드는 하드웨어적인 정의와 소프트웨어적인 정의가 있어 혼동하기 쉽다.
- 하드웨어에서 사용되는 스레드: 하나의 코어가 동시에 처리하는 명령어 단위, CPU 관점에서 설명할때 나오는 스레드
- 소프트웨어 사용되는 스레드: 하나의 프로그램을 독립적으로 실행하는 단위, 코딩 혹은 운영체제관점에서 나오는 스레드
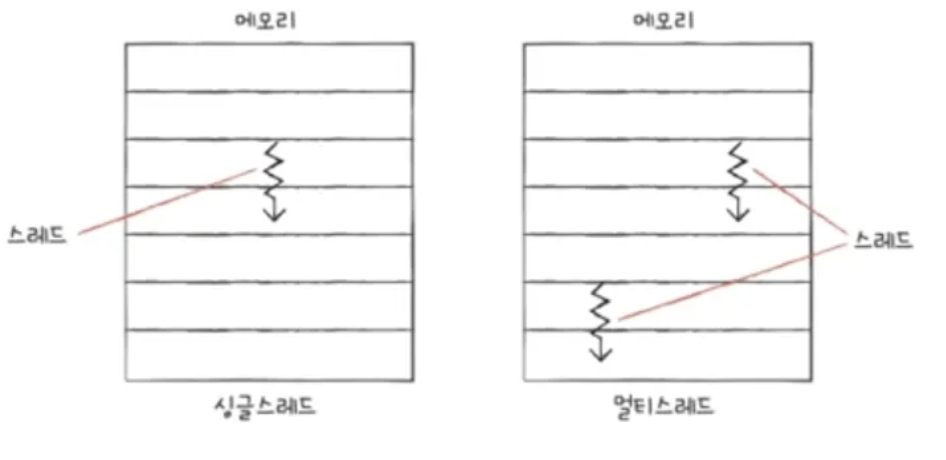
- 멀티 스레드
- 여러개의 하드웨어적인 스레드로 한 코어로 여러 명령어를 실행 가능한 CPU
- 복수의 레지스터 세트
- 멀티 스레드 CPU의 고려 사항 중 가장 핵심적인 요소
- 하나의 명령어를 실행하기 위해 꼭 필요한 레지스터 집합
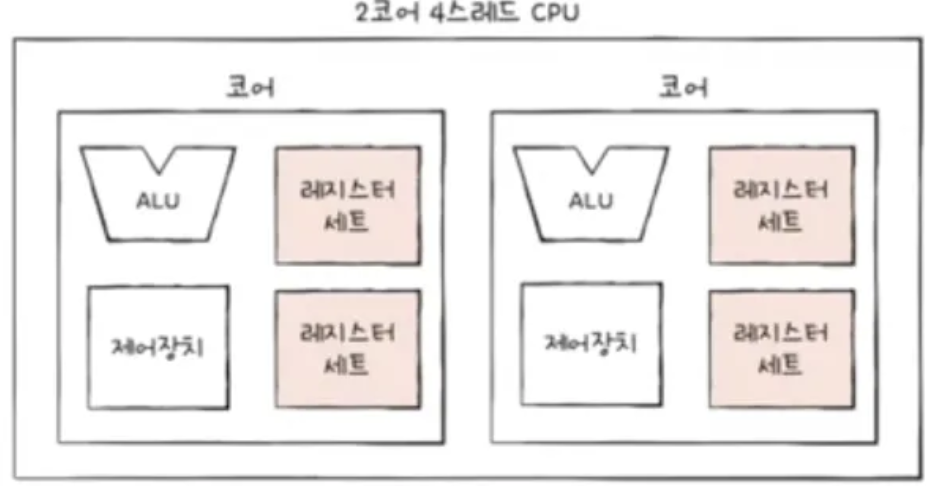
- 메모리 + 메모리에 저장된 프로그램 입장에서 하드웨어 스레드와 코어를 구분하지 못한다.
- 각 하드웨어를 마치 하나의 단일 스레드/ 코어 프로세서로 인식한다.
- 이런 점에서 하드웨어 스레드를 논리 프로세서라고 부른다.
- 8개의 명령어를 인출하고 해석한다면 논리 프로세서가 8개라고 한다.
멀티 코어와 멀티 스레드 차이
- 한 번에 하나의 기능만 가능 (1 core, 1 thread)
- 만약 2개가 있다면 한번에 2개의 기능 가능 (2 core, 2thread)
- 한 번에 세 개의 기능 가능 (1 core, 3 thread)
- 2개가 있다면 (2 core, 6 thread)
- 논리 프로세서의 개수는 6개로 생각함.
명령어 병렬 처리 - 파이프라이닝
- 하나의 CPU가 어떻게 명령어를 처리해야 성능이 높일 수 있는지 알아보자. ⇒ 명령어 병렬 처리
- CPU의 성능을 높일 수 있는 설계
- 명령어 병렬 처리 기법 중 가장 핵심, 명령어 파이프 라이닝
명령어 파이프라이닝
- 원래 용어는 파이프라인(pipelineing)이다. 하지만 네트워크에서도 파이프라이닝이 있기에 헷갈리지 않기 위해 명령어 파이프라이닝이라고 했다.
- 명령어를 동시에 처리하기 위한 기능이다. 이 부분에 따라 성능이 많이 달라진다.
- 하나의 명령어가 처리되는 과정을 비슷한 시간 간격으로 나누면?
- 명령어 인출
- 명령어 해석
- 명령어 실행
- 명령어 저장
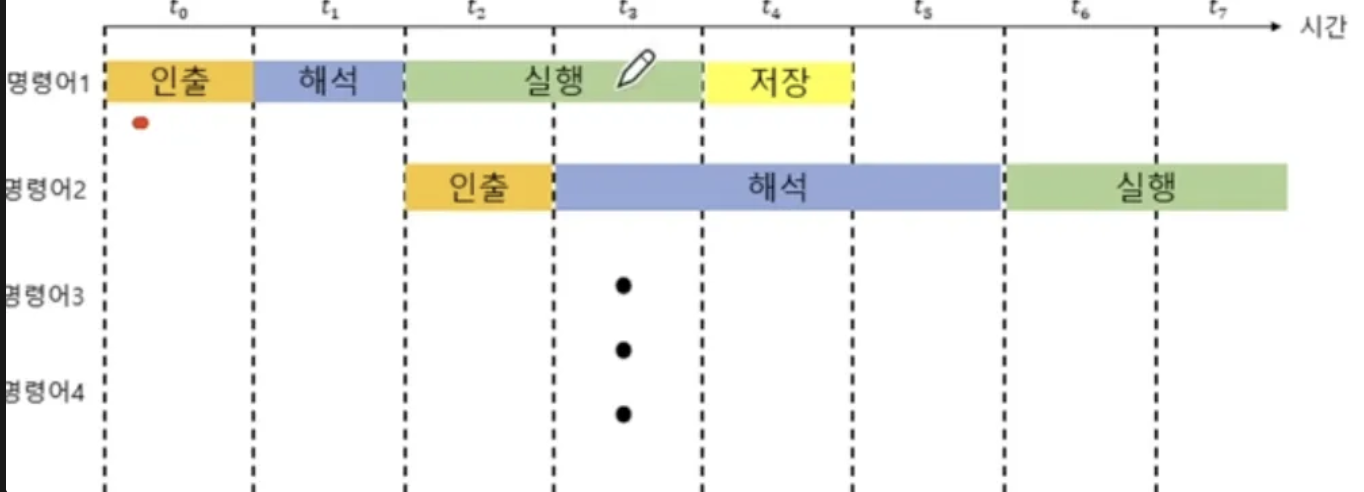
- 위 단계들은 서로 겹치지만 않는다면 한꺼번에 실행 할 수 있다.
- 그림으로 한 번 봐보자.
- 공장의 생산 라인과 같이 명령어가 처리되는 서로 다른 단계를 동시에 처리하는 기법

명령어 파이프라인을 사용하지 않는 경우

파이프라인 실패하는 시나리오, pipeline hazard
- 데이터 위험(data hazard)
- 명령어 간 의존성에 의해 발생
- 예) A 명령어가 저장이 되어야 실행되는 명령어 등
- 데이터가 쓰여진 직후 그 데이터를 읽어드리는 경우 (Read After Write)
- 예) 데이터가 쓰여진 직후 그 데이터를 읽어드리는 경우 (Read After Write) 명령어 1: R1 ← R2 + R3 // R2레지스터와 R3레지스터를 더한 값을 R1에 저장 명령어 2: R4← R1 + R5 // R1레지스터와 R5레지스터를 더한 값을 R4 에 저장 위의 경우는 R1 값이 결정되기전 R1를 더하려고 하면 엉뚱한 R1값을 읽을 수 있다. 인출 당시에는 다른 값, 저장해야 명령에 맞는 값.
- 데이터를 쓴 직후 그 데이터에 내용을 쓰는 경우 (Write After wirte)
- 예 ) 데이터를 쓴 직후 그 데이터에 내용을 쓰는 경우 (Write After wirte) 명령어 1: R1 ← R2 + R3 // R2레지스터와 R3레지스터를 더한 값을 R1에 저장 명령어 2: R1← R4 + R5 // R4레지스터와 R5레지스터를 더한 값을 R1에 저장 명령어 1 저장이 명령어 2 저장보다 늦어진다면, 파이프라인이 여러 개 있는 경우 다른 값이 나온다.
- 데이터를 읽어들인 직후 그 데이터에 새 내용을 쓰는 경우 (Write After Read)
- 명령어 1: R3 ← R2 + R1 // R2 레지스터와 R1레지스터를 더한 값을 R3에 저장 명령어 2: R1← R4 + R5 // R4 레지스터와 R5레지스터를 더한 값을 R1에 저장 명령어 2가 먼저 실행되어 명령어 1값이 달라질 수 있음.
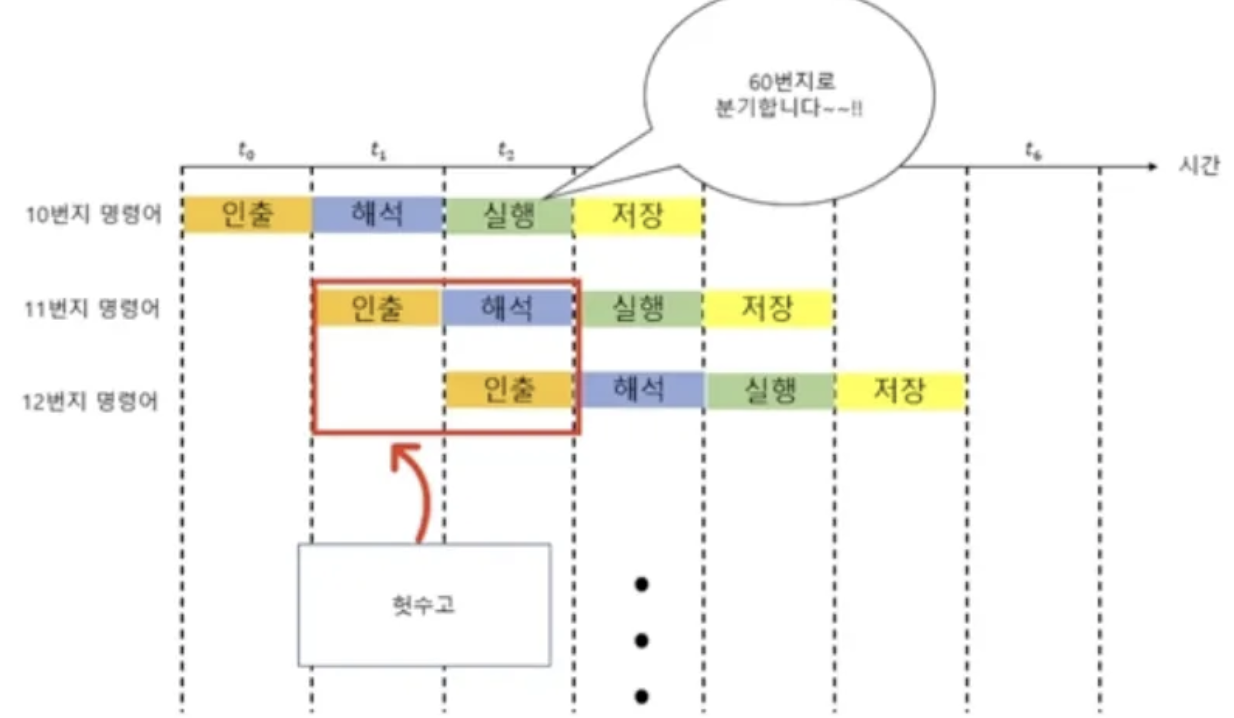
- 제어 위험(control hazard)
- 프로그램 카운터의 갑작스러운 변화에 의해 발생(분기)
- 파이프라인은 1씩 증가하는 것을 상정하였는데 점프하면 의미가 없어지는 것. 10번지에서 분기를 가면 11,12번지는 헛수고임.
- 이런 상황을 방지하기 위해 분기 예측(branch prediction) 기술이 있다.
파이프 라이닝의 발전: 슈퍼스칼라
- 다수의 명령어 파이프라인을 두는 방식
- 여러 명령어 동시 인출/해석/실행/저장이 가능한 CPU
- 이론적으로는 대략 파이프라인의 개수에 비례하여 속도가 높아진다.라고 적혀있다.
- 하지만 여러 위험이 생기기 때문에 실제로는 속도가 높아지지 않는다.

파이프라이닝을 활용하기 위한 CPU 구조
오늘날 컴퓨터의 속도, 성능을 향상시키려면 파이프라이닝을 잘 사용해야 한다.
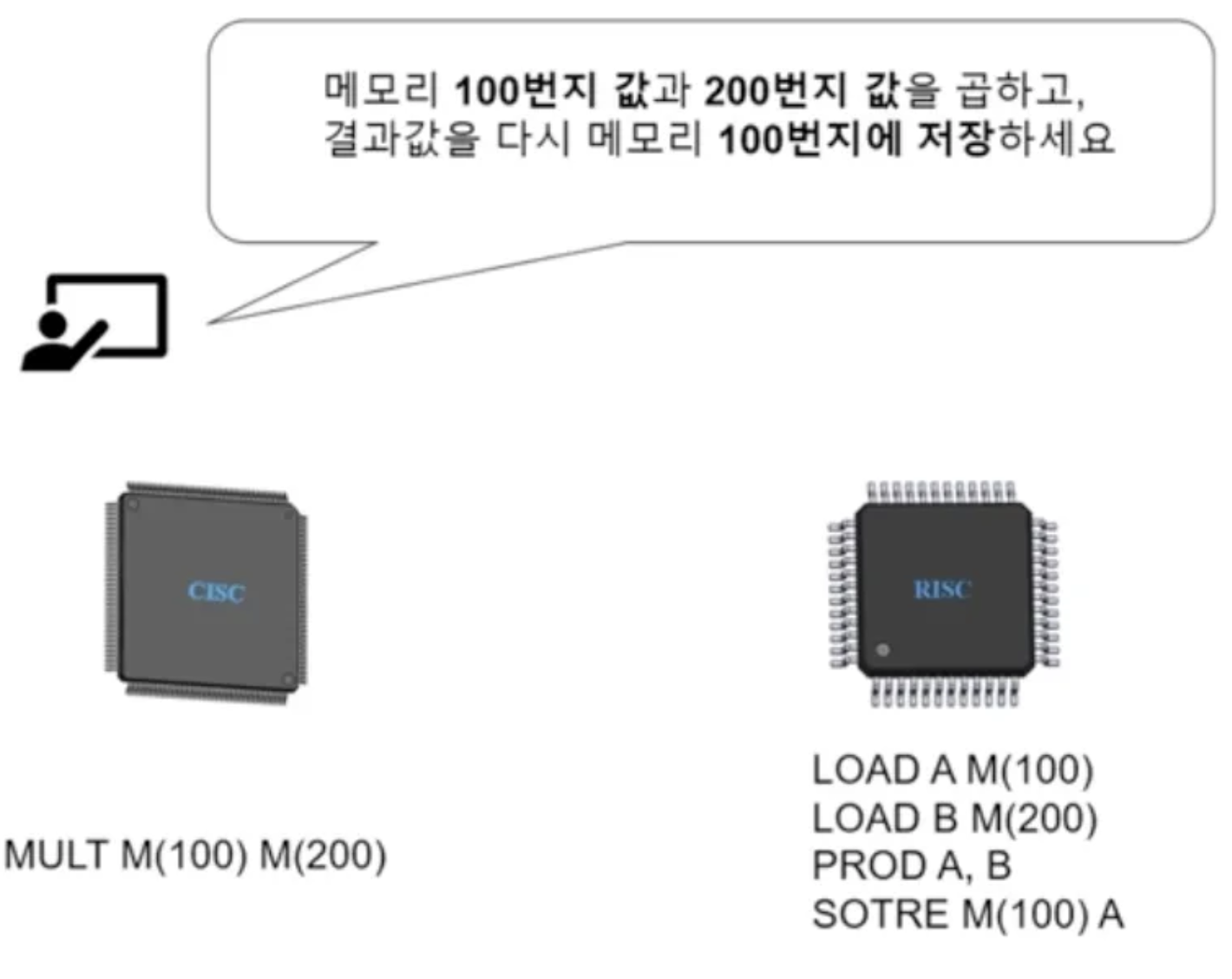
- CISC: Complex Instruction Set Computer (Intel x86 CPU)
- 복잡하고 다양한 기능의 명령어 제공
- 다양한 주소 지정 방식 제공, 다채롭고 강력한 명령어가 존재한다.
- 적은 명령어 수로 명령어 실행 가능 ⇒ 메모리 절약
- 하나의 명령어 실행에 일정하지 않은 클록 수 → 명령어 파이프라이닝에 불리
- 대부분의 명령어는 사용되지 않는다. ⇒ 실제로 사용되는 명령어가 20%밖에 안된다.
- 명령어가 일정하지 않아 파이프라인에 불리하다.
- RISC: Reduced Insstruction Set Computer (ARM CPU)
- 오늘날의 모바일 CPU도 대부분 ARM이 사용된다.
- 짧고 규격화된 명령어 → 명령어 파이프라이닝에 유리, 하나의 명령어가 균일화 되어 있다.
- 대부분 1 클럭내외에 명령어가 처리되는것을 지향한다.
- 적은 수의 명령어 제공
- 메모리 접근 최소화(레지스터 활용) 그래서 load-store구조라고 한다.
- CISC에 비해 더 많은 명령어로 실행 → 컴파일러의 역할이 중요

아래 예제를 보면 CISC, RIS C에 따라 명령어 수가 차이나는것 을 볼 수 있다.
실제로도 그럴까?
- RISC 같은 CISC
- 마이크로 명령어, 규격화된 명령어들을 내보냄.
- CISC 같은 RISC
- 최근 실제 RISC 명령어는 단순하지 않다. 처음에 등장했던 이념이 단순하게 였는데 점점 복잡해지고 있는 것 같다.
비순차적 명령어 처리(Out-of-Order-Execution, OoOE)
- 현대 CPU에서 속도를 개선하는 근본적인 방법
- 명령어 파이프라인의 성능을 높이는 방법
- 파이프라이닝 내의 의존관계가 없는 명령어를 순차적으로 처리하지 않는 방법
- 명령어를 순차적으로만 실행해서는 성능 향상에 실패하는 경우가 있다.
- 아래 명령어는 모두 성능저하 없이 파이프라이닝 가능할까?
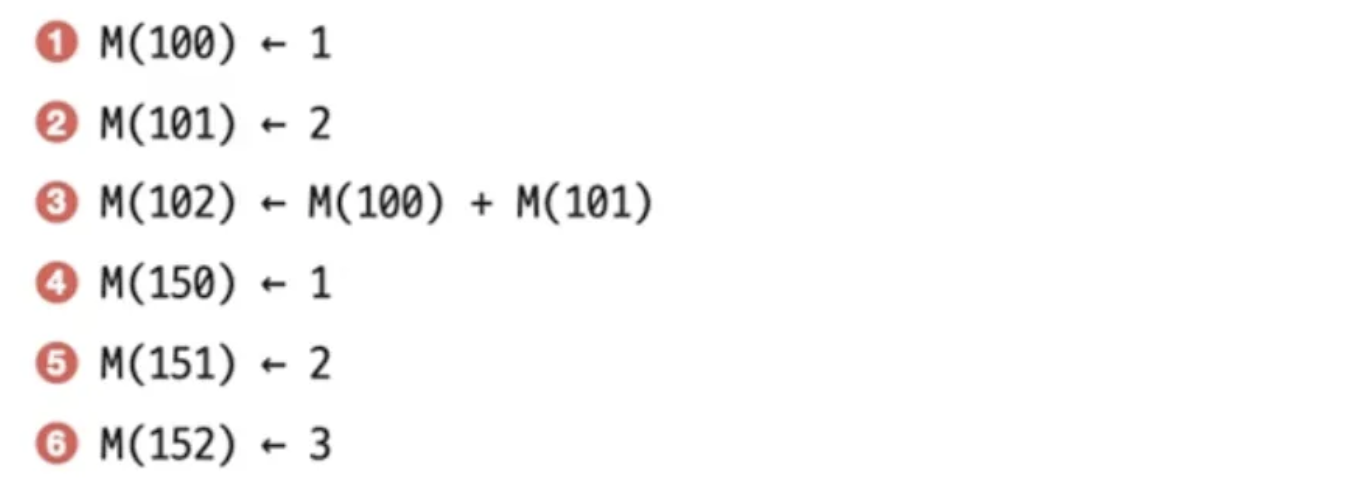
3번째 명령어를 실행하기 위해서는 1번과 2번을 모두 실행하고 저장해야만 3번째 명령어를 실행할 수 있다.
즉, 명령어끼리 의존관계가 있다.
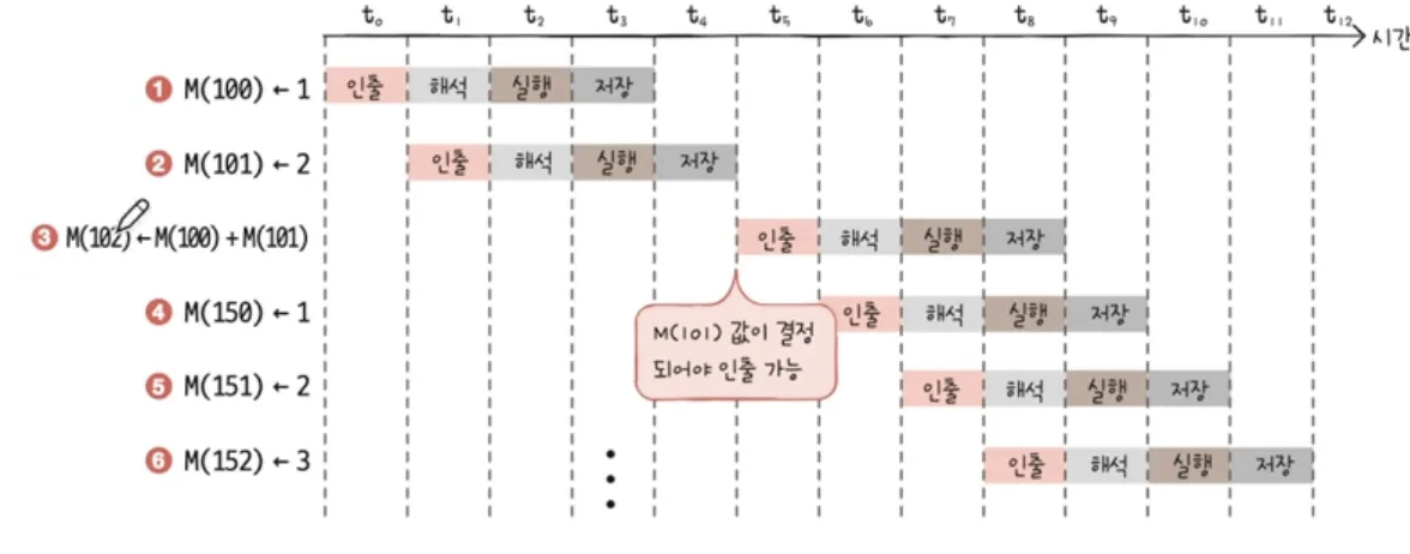
하지만 명령어의 순서를 바꾸어 실행한다면 어떨까?

3번째 명령어 순서를 마지막으로 바꾸어 실행한다면 문제가 없이 실행할 수 있다.
파이프라인에 성공하고 명령어 의존을 자연히 해결한다.

위의 방법을 비순차적 명령어 처리라고 하는 것.
즉 순서를 바꾸어 실행해도 프로그램 실행에 없는 명령어 순서를 바꿈으로써
파이프라이닝의 성능을 높이는 기능을 비순차적 명령어 처리라 한다.
순서를 바꿀 수 있는 판단을 하는 것은 비순차적 명령어 처리가 가능한 CPU가 판단한다.
즉, 비순차적 명령어 처리를 잘할 수 있는 CPU가 성능이 좋다.
- APPLE의 실리콘 M1, M2가 높은 성능을 보이는 이유는 RICS 구조이기도 하지만 비순차적 명령어 처리를 잘하는 CPU라는 발표도 있다.
결론
이렇게 컴퓨터구조 중 가장 중요한 부품인 CPU에 대해 공부하였다.
컴퓨터의 성능을 끌어올리기 위한 여러가지 방법이 있다.
- 클럭 수 향상, 오버클럭킹
- 코어와 멀티코어
- 스레드와 멀티스레드
- 파이프라이닝, 명령어 병렬처리(CISC, RISC)
- 비순차적명령어처리(Out-of-Order-Execution, OoOE)
하드웨어로도 소프트웨어로도 컴퓨터의 성능을 올릴 수 있다.
728x90
'Computer Science > Computer Architecture' 카테고리의 다른 글
| [Computer Science] [컴퓨터구조] Memory (2) | 2024.12.23 |
|---|---|
| [Computer Science] [컴퓨터구조] 보조기억장치와 입출력장치 (1) | 2024.12.20 |
| [Computer Science] [컴퓨터구조] CPU (0) | 2024.12.14 |
| [Computer Science] [컴퓨터 구조] 데이터 (1) | 2024.12.13 |
| [Computer Science] [컴퓨터구조] 명령어 (4) | 2024.12.12 |