
CS 공부 시작
이번주부터 매주 일주일에 한 번 컴퓨터공학 스터디를 진행하기로 하였다.
진행 방식은 컴퓨터 공학에 관련된 강의를 구매하여 각자 정리를 하고 Chapter 한개씩 발표를 하여 본인이 이해한 내용 혹은 이야기 해보고 싶은 주제를 10분 정도 발표를 하여 서로 이야기를 하는 방식이다. 이번주 공부해야할 분량은 컴퓨터 구조 과목에서 명령어, 데이터, CPU(1)이다.
CPU는 분량이 많아서 반을 나누어 학습을 하기로 했다.
그 중 나는 CPU(1)를 발표하기로 하였기에 CPU에 대한 간단한 자료를 만들려고 한다.
컴퓨터 구조에서 제일 첫번째 Chapter인 명령어에 대해서 정리를 하였다.
명령어
프로그램을 이루는 두 정보에서 명령어는 컴퓨터를 동작시키는 실직적인 정보이고
데이터는 명령어의 대상이 된다. 즉 명령어의 재료인것.
컴퓨터는 소스코드를 언제 이해할까?
개발자들이 고급언어(C,C++,JAVA, Python등)를 이용하여 소스코드를 작성하고 실행을 하면 컴퓨터가 코드에 맞게 동작을 한다.
그러면 컴퓨터는 소스코드를 이해하는 것 일까? 아니다!
컴퓨터는 명령어를 이해하는 것이다. 이것이 무슨 말이냐면 소스코드는 실행되기 전 명령어(with 데이터)로 변환되어 실행이 되는 것이다.
소스코드란
소스코드는 사람(개발자)가 이해하기 편하게 만들어진 언어이다.
사람은 이진수로 만들어진 컴퓨터 언어를 보기가 너무너무어렵다.. 컴퓨터와 소통을 하기 위해서 고급언어를 사용해서 이야기를 하는 것이다.
저급언어
기계어와 어셈블리어는 통일되지 않는다.
이게 무슨말이냐면 CPU의 종류에 따라서 기계어가 달라지고 고급언어에 따라서 또 어셈블리어가 달라 질 수 있다.

기계어: 기계어는 컴퓨터가 직접적으로 이해하는 언어이다. 이진수로 표현된다.

어셈블리어: 기계어를 사람이 읽기 조금이라도 편하게 변한시킨 언어이다. 예시를 한 번 봐보자.

변환 방식
고급언어에서 저급언어로 변환이 되는 대표적인 방식은 컴파일과 인터프리트가 있다.
그렇다고 이 두가지만 변환하는 방식이 있는 것이 아닌 다른 종류의 변환 방식도 있다.
그러면 둘의 차이점은 어떻게 될까

컴파일
컴파일 방식은 소스코드 전체가 컴파일러에 의해 검사, 목적 코드(object code)로 변환한다.
C나 C++이 해당된다.
컴파일의 종류도 다양하다. gcc, clang, VisualStudio 등등

인터프리트
인터프리는 소스 코드 한줄씩 인터프리터에 의해 검사하고 목적 코드로 변환 한다
Python, JavaScript가 해당된다.
이 때 중요한 것이 칼로 자르듯이 한줄씩 검사를 하는 것이 아니다!
이 점을 기억하자. 많은 사람들이 칼로 자르듯 구분되는 개념이라고 생각한다.
결론
그리고 위의 컴파일과 인터프리트 방식을 모두 가진 고급언어도 있다.
JAVA와 Python도 사실 해당한다.
명령어 관찰해보기
명령어가 어떻게 실행되는 지 관찰을 해보자.
위의 사이트를 접속하면 소스코드가 어떻게 명령어로 변환이 되는 지 이해하기 쉽다.
JAVA 언어를 선택하여 a와 b를 더해주는 소스코드를 작성해봤다.
오른쪽에 어셈블리어가 나오게 된다

아래는 C언어로 소스코드를 작성해봤다
같은 C언어의 소스코드라도 CPU의 종류에 따라서 혹은 컴파일러의 종류에 따라서 변환되는 명령어의 결과 달라질 수 있다.
오른쪽 어셈블리어 위에있는 x86-64는 intel 혹은 AMD CPU이고 명령어를 해석하는 방법 중 하나이다. gcc는 컴파일러의 종류이다.
왼쪽은 gcc 컴파일러를 사용한 것이고 오른쪽은 clang 컴파일러를 사용하였다.
어셈블리어가 어떤 컴파일러를 사용하는 것에 따라 달라지는 것을 확인할 수 있다.
소스코드에 있는 색과 어셈블리어의 색과 일치하는 것이 변환된 것을 뜻한다.

이렇게 소스코드가 어떤 컴파일러를 사용하는 지 혹은 cpu를 사용하는지에 따라 어셈블리어가 다르게 나오는 것을 확인할 수 있다.
명령어의 구조
일상적으로 명령어를 사용한다면
무엇을 대상으로 무엇을 수행하라 로 이루어진다.
크게 명령의 대상과 명령의 동작으로 이루어져 있는것.
아래 이미지는 실제 컴퓨터를 동작시키는 명령어이다.
명령어는 “오퍼랜드로 연산코드를 수행하라" 이다.
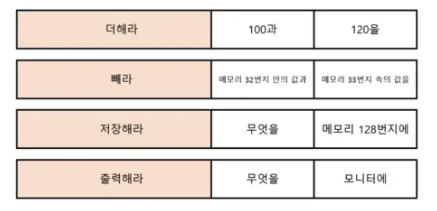
연산코드(OP-CODE)
- 오퍼랜드로 수행할 동작을 의미
- 피연산자라고도 한다.
- CPU마다 연산코드가 다를 수 있다.
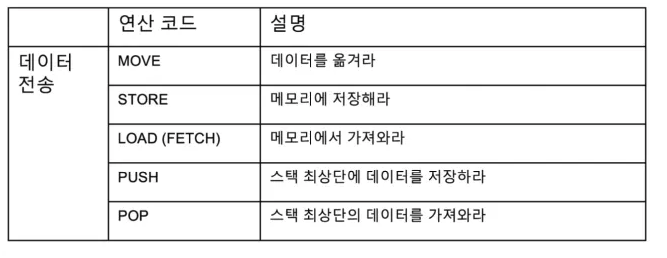
- 아래는 연산코드 중 데이터 전송을 담당하는 연산 코드 설명이다. 연산 코드는 데이터 전송, 산술/논리 연산, 제어 흐름 변경, 입출력 제어 등이 있다.
오퍼랜드
- 무엇을 대상으로, 명령어를 수행할 대상이 되는 것
- 데이터(대상)이 직접 명시되기도 하고, 대상의 위치가 명시되기도 함. (이 때 대상의 위치가 명시 되는 것을 잊지말자 중요하다)
- 대상의 위치: 레지스터의 이름(cpu에 있는 작은 연산장치), 메모리 주소이다.
X = (A+B) * C라는 명령어가 있을 때 오퍼랜드의 개수에 따라 단계가 달라질 수 있다.
오퍼랜드가 2개가 있다면 4개의 단계를 거쳐 실행이 되고 오퍼랜드가 3개가 있다면 2개의 단계를 거쳐 실행이 된다.
주소 지정
- 명령어는 오퍼랜드로 연산 코드를 수행하라 이다.
- 연산코드의 대상이 되는 데이터를 찾아가는 방법이 주소 지정이다.
- 주소 지정은 cpu마다 차이가 있고 다양한 주소 지정 방식이 있다.
- 왜 데이터를 직접 명시하지 않고 위치를 명시할까? 명령어의 길이는 한정되어 있기 때문이다.
- 명령어에서 연산코드가 4bit라고 한다면 하나의 오퍼랜드 필드로 표현할 수 있는 데이터의 크기는 2^6 → 64이다. 오퍼랜드가 많아질수록 데이터의 크기는 점점 작아진다.
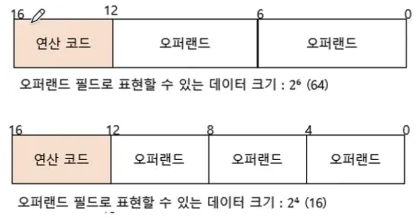
- 이러한 문제를 해결하기 위해 오퍼랜드에 대상이 되는 데이터를 직접 명시하기 보다는 메모리의 주소, 레지스터 주소를 명시한다면 표현할 수 있는 데이터의 크기를 더 크게 가져갈 수 있다.
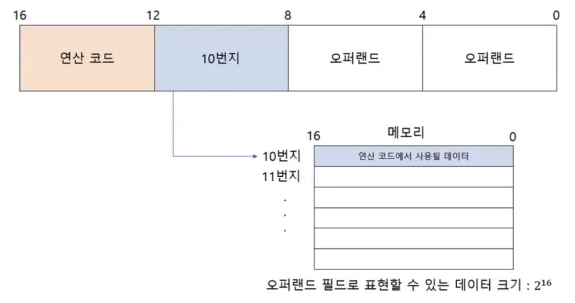
유효 주소
연산코드에 사용할 데이터가 저장된 윛, 즉 연산의 대상이 되는 데이터가 저장된 위치를 뜻한다.
- 주소 지정
- 유효 주소를 찾는 방법
- CPU마다 차이가 있다
주소지정방식
- 즉시 주소 지정
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시
- 가장 빠른 주소 지정 하지만 데이터 크기에 제한
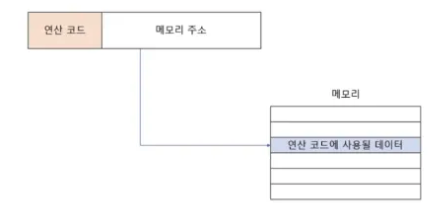
- 직접 주소 지정
- CPU가 레지스터에 접근 속도보다 메모리에 접근하는 속도가 훨씬 더 느리다. 그래서 메모리에 접근해야하는 시간이 생긴다.
- 오퍼랜드 필드에 유효 주소(연산에 사용될 데이터가 저장된 메모리 주소) 명시
- 오퍼랜드 필드로 표현 가능한 메모리 주소 크기에 제한
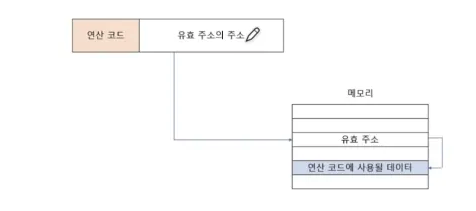
- 간접 주소 지정
- 최근 메모리 주소 크기도 늘어나고 있다.
- 오퍼랜드 필드에 유효 주소의 주소 명시
- 두번 접근해야하여 속도가 비교적 느리다
- 유효 주소 크기에 제한은 없다.
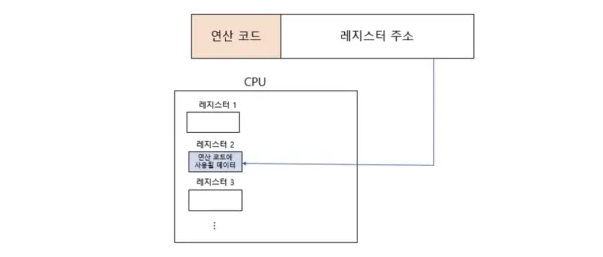
- 레지스터 주소 지정
- 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시한다.
- 레지스터가 CPU내에 있으니 레지스터 접근은 메모리보다 빠르다!
- 직접주소지정보다 빠르게 접근이 가능하다.
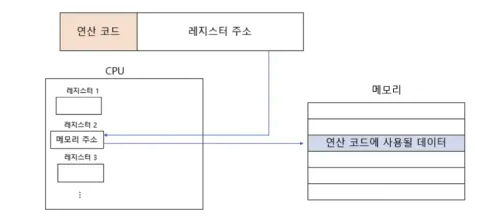
- 레지스터 간접 주소 지정
- 연산에 사용할 데이터를 메모리에 저장하고
- 그 주소를 저장한 레지스터를 오퍼랜드 필드에 명시
- 메모리 접근은 한 번만 가능하기 때문에 간접주소지정보다 더 빠르다.
실제로 어셈블리어 코드를 보면 대부분 레지스터들이 많이 있다.
'Computer Science > Computer Architecture' 카테고리의 다른 글
| [Computer Science] [컴퓨터구조] Memory (2) | 2024.12.23 |
|---|---|
| [Computer Science] [컴퓨터구조] 보조기억장치와 입출력장치 (1) | 2024.12.20 |
| [Computer Science] [컴퓨터구조] CPU(2) (0) | 2024.12.16 |
| [Computer Science] [컴퓨터구조] CPU (0) | 2024.12.14 |
| [Computer Science] [컴퓨터 구조] 데이터 (1) | 2024.12.13 |